Reactアプリを5分でGitHub Pagesにデプロイする方法
本記事をお読みいただく前の注意点
本記事は、ReactアプリをGitHub Pagesにデプロイする方法を説明することが目的の内容となっています。
そのため、記事内ではGitとGitHub、GitHub Pagesの使い方については説明を割愛しています。ご了承ください。
GitHub Pagesについて
以前、私のブログでGitHub Pagesを使ってサイト公開する流れを記事にしました。 GitHub Pagesに関する基本的な内容はそちらで解説していますので、「GitHub Pagesって何?」ということから知りたい方は、そちらの記事をご覧ください。
前提条件
ReactアプリをGitHub Pagesにデプロイする手順
それでは、作成したReactアプリケーションを、GitHub Pagesでホスティングする手順を紹介します。 初心者でも簡単にデプロイできるよう、各ステップを丁寧に解説しています。
ステップ1:package.jsonファイルの設定
まず、package.jsonファイルを編集して、homepageプロパティを追加します。これにより、アプリケーションがGitHub Pagesで正しいパスで動作するようになります。
package.jsonファイルを開き、次のようにhomepageプロパティを追加します。ここで、<username>と<repository>をご自身のGitHubユーザー名とリポジトリ名に置き換えてください。
{ "name": "my-app", "version": "0.1.0", "private": true, "homepage": "https://<username>.github.io/<repository>", ... }
この設定により、アプリケーションのビルド結果がGitHub Pagesで正しくホストされるようになります。
ステップ2:gh-pagesパッケージのインストール
次に、デプロイ作業を簡単にするためにgh-pagesパッケージをインストールします。gh-pagesは、ビルドされた静的ファイルを自動的にGitHub Pagesにデプロイするためのツールです。
以下のコマンドを実行してgh-pagesをインストールします。
npm install --save-dev gh-pages
インストールが完了したら、package.jsonファイルにデプロイスクリプトを追加します。この設定により、コマンド一つでアプリケーションをビルドし、デプロイできるようになります。
package.jsonのscriptsセクションを以下のように編集してください。
{ "scripts": { "predeploy": "npm run build", "deploy": "gh-pages -d build", ... } }
追加したスクリプトの意味は次の通りです。
- predeploy:
deployスクリプトを実行する前に、自動的に
npm run buildコマンドを実行してbuildディレクトリにアプリケーションをビルドします。buildディレクトリには、HTML、CSS、JavaScriptなどの静的ファイルが生成されます。 - deploy: gh-pagesコマンドを使用して、buildディレクトリの内容をgh-pagesブランチにデプロイします。コマンドを実行すると、自動的にbuildディレクトリ内のファイルをgh-pagesブランチにコミットし、リモートリポジトリにプッシュします。これにより、GitHub Pagesでウェブサイトがホストされます。
ステップ3:デプロイ
ここまでの設定が完了したら、いよいよアプリケーションのデプロイです。以下のコマンドを実行してアプリケーションをデプロイします。
npm run deploy
ステップ4: GitHub Pagesの設定確認
デプロイが完了したら、GitHubリポジトリの「Settings」→「Pages」セクションに移動して、以下の手順でデプロイされたブランチがgh-pagesブランチになっていることを確認します。 (通常、この設定は自動的に行われますが、しっかりとデプロイされているどうか確認することをお勧めします)
リポジトリの「Settings」タブを開く: GitHubリポジトリのトップページで、「Settings」タブをクリックします。
「Pages」セクションに移動: 左側のメニューから「Pages」を選択します。
デプロイされたブランチの確認: 「Build and deployment」セクションで、デプロイされたブランチがgh-pagesブランチになっていることを確認します。
ステップ5: デプロイ結果の確認
設定が完了したら、https://<username>.github.io/<repository>にアクセスして、デプロイされたReactアプリケーションが正しく表示されているかどうかを確認します。
おわりに
ReactアプリをGitHub Pagesにデプロイする方法をご紹介しました。 どうでしょう、慣れれば5分程度で完了する程度の簡単な作業ではなかったでしょうか。 ReactアプリケーションをGtiHub Pages上にデプロイする場合、公開用のファイルをビルドして、リポジトリにコミットし、GitHub上でページ公開の作業を行う必要があります。 それが、gh-pagesパッケージを利用することで、それらの手順を全て自動でおこなってくれます。 作成したReactアプリケーションを、サーバーを借りずに無料で手軽に公開したい場合には、こちらでご紹介した方法でパパッとGitHub Pages上に公開できますので、ぜひ活用してみてください。
【初心者向け】GitHub Pagesを使ってサイトを公開する流れ
本記事をお読みいただく前の注意点
本記事は、GitHub Pagesの使い方を説明することが目的の内容となっています。
そのため、記事内ではGitとGitHubの使い方については説明を割愛しています。ご了承ください。
GitHub Pagesとは
GitHub Pagesは、GitHub上からHTML/CSS/JavaScript で作ったサイトを公開することができるサービスです。サーバーを契約しなくても、GitHub上から無料で手軽にサイトを公開できるため、ポートフォリオサイトや自己紹介ページなどを公開するといった用途に活用できます。
一方、PHPやPythonといった言語やWordPressなどで作られたサイトには使えない、容量や転送量に制限がある、アクセス制限や商用利用ができないという制約もあるため、注意が必要です。
GitHub Pagesで制限されていることの詳細については以下の公式ドキュメントを参照してみてください。
・GitHub Pages について - GitHub Docs https://docs.github.com/ja/pages/getting-started-with-github-pages/about-github-pages
サイトを公開する手順
まず、公開したいサイトのソースをローカル環境で作成していきます。
その上で、GitHub上でWeb サイトのソースの保管場所となるリポジトリを作成します。
そこまでできたら、制作したサイトをリポジトリにアップロードして、サイトの公開設定をすれば、GitHub上でサイトのURLを発行してくれる、という仕組みになっています。
サイトのURLは以下のようになります。
https://<username>.github.io/<repository>
もしご自身で所有しているドメインがあれば、その独自ドメインを設定して公開することも可能です。記事の最後に、独自ドメインの設定方法を記載していますので参考にしてください。(ドメインの取得方法については記載していません。ご了承ください。).
なお、これから説明する作業を進めるには、事前にGitHub のアカウントを作成し、GitHubにログインしておく必要があります。
まだ、アカウントを持っていない人は下記URL にアクセスしてアカウントを作成し、GitHubにログインしてください。
・Join GitHub https://github.com/signup
リポジトリを作成する
github.com/new にアクセスしてリポジトリを作成してください。
リポジトリの可視性については、 [Public]を選択します。 [Private]でもサイトは公開できますが、Proアカウントが必要になります。Proアカウントは使用料が発生してくるため、よほどの理由がない限り、個人利用であれば無料で利用できるPublicを選択しておけばOKです。
GitHub Pagesの可視性についてより詳しく知りたい方は、以下の公式ドキュメントを確認してください。
参照元:https://docs.github.com/ja/enterprise-cloud@latest/pages/getting-started-with-github-pages/changing-the-visibility-of-your-github-pages-site
公開するサイトをアップロードする
GitHub上に、サイトを構成するHTML、CSS、画像ファイルなどをアップロードしていきます。
ローカルからプッシュする方法と、GitHub上で直接ファイルをアップロードする方法の2パターンがあります。お好きな方法でアップロードしてください。
サイトを公開する
リポジトリ名の下にある [Settings] をクリックします。
![]()
サイドバーから [Pages] をクリックします。

Branch のところにある項目で、公開元となるブランチとフォルダを選択します。ここでは main、そして /(root) として Save をクリックします。
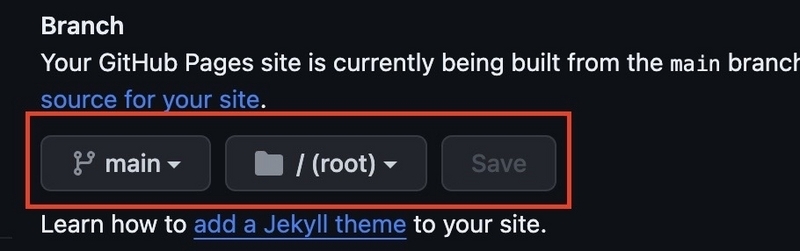
そうすると、サイトを公開するための処理が実行されていきます。進捗は [Actions] タブで確認することができます。
![]()
処理中はIn progressと表示されるので、処理が終わるまで待ちます。
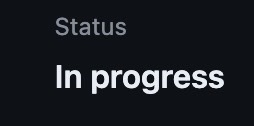
処理がすべて終わるとStatusの表示が Success になります。早ければ数秒、場合によっては数分かかることもあるようです。

StatusがSuccess になったら、 [Settings] タブにもどって、サイドバーの [Pages] をクリックします。
そうすると、「Your site is live at」の後にhttps://<username>.github.io/<repository>の形式のURL が発行されていて、[Visit site]をクリックすれば、別タブでサイトを確認することができます。
以上でサイトの公開は完了です。おつかれさまでした。
この後の記事後半では、サイト公開後の更新作業や独自ドメインの設定について説明します。
サイトを更新する
ローカル環境上でファイルを編集します。
その後、GitHub上に編集したファイルをアップロードすれば OK です。「公開するサイトをアップロードする」の手順と同様、ローカルからプッシュするか、GitHub上で直接ファイルをアップロードするか、お好きな方法で更新してください。
アップロード後は、サイト公開時と同様、GitHub上で処理が実行され、その進捗は [Actions] タブで確認することができます。StatusがSuccess になったら完了です。
サイトURLからページを開き、更新内容が反映されているか確認してください。
サイトの公開を停止する
サイトの公開を一時的に停止したくなった場合、 [Settings] タブ→ [Pages] と進んで、「Visit site」ボタンの右側にあるボタンをクリックし、「Unpublish site」をクリックすれば OK です。

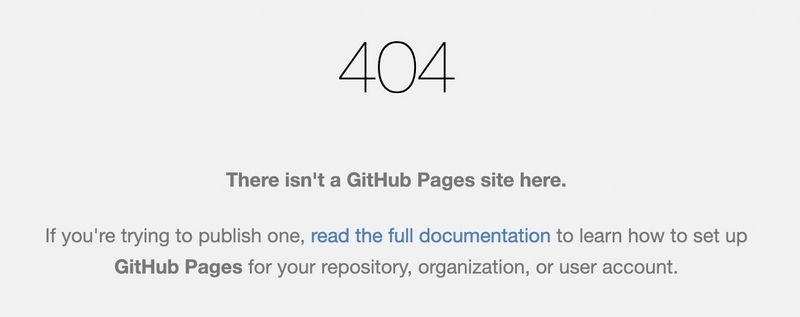
これでサイトが非公開になったので、サイトURLを再読み込みしてページ上に404が表示されることを確認してください。
サイトを再公開する
一時的に停止したサイトを再度公開したい場合、[Actions] タブをクリックして、「pages build and deployment」という処理をクリックします。
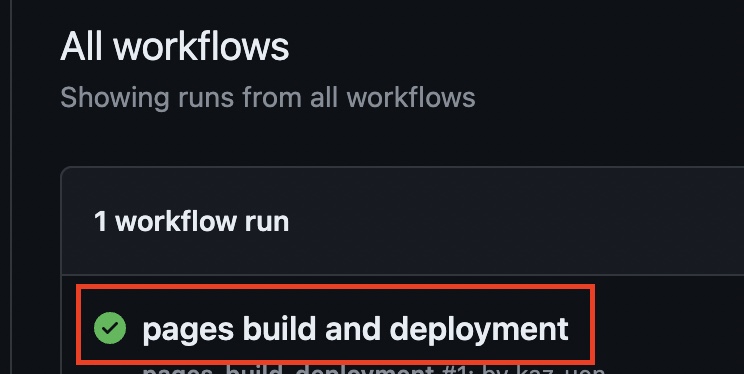
その上で画面右上にある「Re-run all jobs」ボタンをクリックします。
以下のようなポップアップが表示されるため、「Re-run all jobs」ボタンをクリックするとサイト公開の処理を再度実行してくれます。
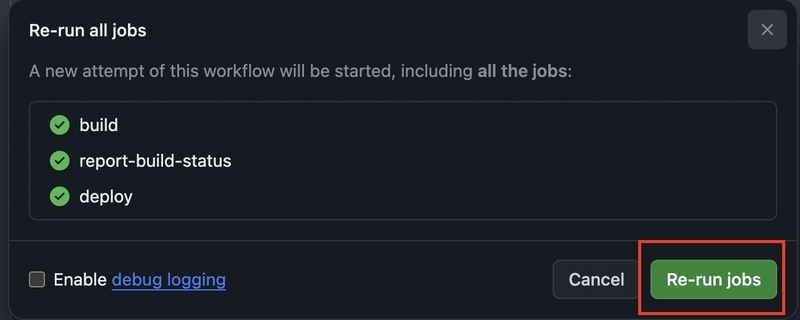
StatusがSuccess になったらサイトURLを開いてページが表示されれば完了です。
独自ドメインを設定する
GitHub PagesのURLには、自身で所有している独自ドメインを設定することができます。
サポートされている独自ドメインの種類は以下のとおりです。
| サポートされている独自ドメインの種類 | 例 |
|---|---|
| www サブドメイン | www.example.com |
| カスタム サブドメイン | blog.example.com |
| Apex ドメイン | example.com |
独自ドメインを設定するには、 [Settings] タブ→ [Pages] と進んで、設定画面内に「Custom domain」という項目があるため、取得したドメインを入力して「Save」ボタンをクリックしたら完了です。

おわりに
GitHub Pagesを使ったサイトの公開方法をご紹介しました。
レンタルサーバーの契約やドメインの取得には費用がかかりますが、GitHub Pagesを使えば、無料で手軽にサイトが作って公開できます。
費用をかける必要はない、まずはとりあえずサイトを公開したいというケースでは、GitHub Pagesを活用してみるのも手かと思います。
駆け出しエンジニアが知っておくべきWeb技術の基本用語(その2)
はじめに
以前、「駆け出しエンジニアが知っておくべきWeb技術の基本用語」という記事を投稿しましたが、今回はその第2弾です。
前回取り上げた用語は、プログラミング学習の前段階で知っておくべきような内容のものでしたが、今回はより実践寄りの用語を掲載しています。
Web技術の用語は、実際に自らサイトやシステムを構築する中で、これらの知識が必要になった時に改めて振り返ることで、
本当の意味でその内容を理解できると思います。
今回は、未熟ながらも普段フロントエンドエンジニアとして働いている自分自身の知識を整理する意味もあったりします。
もし書いている内容で間違っている点などありましたら、コメントで指摘して頂けると非常に助かります。
1. ステートフル (Stateful):
システムやプロトコルが前回の状態やアクションを覚え、それに基づいて次の動作を判断する性質を指します。これは、連続するアクションやリクエストに対して特定の状態が保持され、その状態が後続のアクションやリクエストに影響を与えるという考え方です。
ステートフルなシステムは、ユーザーの活動やセッション情報などをトラッキングし、それに基づいて個々のユーザーやクライアントに対して異なる振る舞いをすることがあります。
特徴:
- 状態の保持:
ステートフルなシステムは、ユーザーのセッション情報や特定の状態を保持します。これにより、連続するアクションやリクエストにおいて一貫性を保ちながら振る舞いが変わります。
- コンテキストの理解:
システムが前回のユーザーアクションを記憶しているため、ユーザーのコンテキストを理解し、よりパーソナライズされた体験を提供できます。
- セッション管理:
ユーザーセッションをトラッキングし、ログイン状態やセッションの有効期限などを管理することができます。
使用例:
- ログインセッション:
ウェブアプリケーションでのユーザーのログインセッションはステートフルな例です。ユーザーがログインすると、その情報がセッションに保存され、後続のリクエストにおいてユーザーが認証された状態が維持されます。
- カートの管理:
オンラインショッピングサイトにおいて、ユーザーが商品をショッピングカートに追加すると、その情報がセッションに保存され、ユーザーがサイトを閉じても再度開いた際にカートの中身が維持されます。
利点:
- パーソナライズされた体験:
ユーザーごとに異なる状態を保持できるため、パーソナライズされた体験を提供しやすいです。
- セキュリティ向上:
セッション情報やユーザーステートを管理することで、セキュリティを向上させることができます。
欠点:
- サーバー負荷:
サーバーはセッション情報を保持する必要があるため、大量のユーザーが同時に利用する場合、サーバー負荷が増加する可能性があります。
- スケーラビリティの課題:
ステートフルな設計はスケーラビリティの課題を引き起こすことがあり、大規模なシステムでは管理が難しくなることがあります。
ステートフルな設計は、特定の用途や要件に応じて有効であり、ウェブアプリケーションやセッションベースのアプリケーションなどで一般的に使用されています。
2. ステートレス (Stateless):
システムやプロトコルが前回の状態を覚えず、各リクエストやアクションを独立して処理する性質を指します。このアプローチでは、各リクエストはその都度独立して処理され、前回の状態や情報は保持されません。これにより、システムは特定のユーザーの過去の活動や状態に依存せず、各リクエストを個別に処理することが可能です。
特徴:
- 状態の非保持:
ステートレスなシステムでは、前回の状態やセッション情報が保持されません。各リクエストは独立して処理されます。
- 独立性:
各リクエストは前回のリクエストとは無関係であり、それぞれが個別に処理されるため、相互の影響が少ないです。
使用例:
- HTTPプロトコル:
HTTPはステートレスなプロトコルであり、各HTTPリクエストは他のリクエストとは無関係に処理されます。これにより、ウェブサーバーはクライアントの状態を保持せずにリクエストに応じたレスポンスを生成します。
- RESTful API:
RESTfulなAPIは通常ステートレスなデザインを採用しています。クライアントがAPIに対してリクエストを送り、サーバーがそれに対してレスポンスを返すが、クライアントの前回のリクエストに基づいてサーバーが状態を保持することはありません。
利点:
- スケーラビリティ:
ステートレスなアーキテクチャはスケーラビリティが向上しやすいです。各リクエストが独立しているため、負荷分散や並列処理がしやすくなります。
- シンプルな実装:
ステートレスなシステムは状態を保持する必要がないため、実装がシンプルになりがちです。各リクエストを単純に処理することができます。
欠点:
- 情報の共有が難しい:
各リクエストが独立しているため、クライアントやサーバー間で前回の情報を共有するのが難しい場合があります。
- セッション管理の複雑さ:
ステートレスなシステムではセッション管理が複雑になりがちで、一連の操作を追跡するための手段が必要です。通常はクライアントがセッション情報を持つことがあります。
ステートレスなデザインは一般的に、分散システムやクラウドベースのアプリケーション、マイクロサービスなどで利用されることがあります。それにより、システムが柔軟で拡張性があり、単純なリクエスト/レスポンスモデルを実現できます。
3. リクエスト (Request):
クライアントがサーバーに向けて特定のアクションやデータの提供を要求するための通信メッセージです。主にクライアント(要求者)が行い、それに対してサーバー(受信者)が応答します。リクエストは通信プロトコルによって構造化され、要求された操作やデータの詳細が含まれています。
リクエストの構成要素:
- HTTPメソッド:
リクエストが実行したい操作を示すためのメソッドです。代表的なHTTPメソッドには、GET(データの取得)、POST(データの送信)、PUT(データの更新)、DELETE(データの削除)などがあります。
- URI(Uniform Resource Identifier)またはURL(Uniform Resource Locator):
リクエストが対象とするリソース(データやサービス)を識別するための識別子です。URIやURLは、サーバー上の特定のエンドポイントやリソースを指定します。
- ヘッダー(Headers):
リクエストに関連するメタ情報や設定が含まれる部分です。例えば、ブラウザの種類、クライアントが受け入れ可能なコンテンツタイプ、認証情報などが含まれます。
- ボディ(Body):
リクエストにデータが含まれる場合、それがボディに格納されます。主にPOSTやPUTメソッドで利用され、フォームデータ、JSON、XMLなどがボディに含まれます。
具体例:
- HTTP GETリクエスト:
ウェブブラウザが特定のウェブページにアクセスするときのGETリクエストは以下のようになります。
GET /example-page HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
この例では、GETメソッドが使用され、/example-pageがリクエスト対象のURIです。
- HTTP POSTリクエスト:
フォームデータをサーバーに送信するPOSTリクエストの例は以下のようになります。
POST /submit-form HTTP/1.1 Host: www.example.com Content-Type: application/x-www-form-urlencoded User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 username=johndoe&password=secretpassword
この例では、POSTメソッドが使用され、ボディにはフォームデータが含まれています。
リクエスト処理の流れ:
(1) クライアントがリクエストを生成:
クライアント(通常はブラウザやアプリケーション)がユーザーの操作や特定のイベントに基づいてリクエストを生成します。
(2) リクエスト送信:
クライアントが生成したリクエストが対象のサーバーに送信されます。この際、URI、HTTPメソッド、ヘッダー、ボディなどが含まれます。
(3) サーバーがリクエストを処理:
サーバーは受け取ったリクエストを解釈し、対応する処理を行います。これにはデータの取得、処理、保存などが含まれます。
(4) サーバーからのレスポンス:
サーバーは処理結果を含んだレスポンスを生成し、それがクライアントに送信されます。
リクエストとレスポンスは通信プロトコルに基づいて標準的な形式でやり取りされ、これによりクライアントとサーバーが相互にコミュニケーションを行います。
4. レスポンス (Response):
サーバーがクライアントに対して送るデータや情報のことです。通常、クライアントがサーバーに送ったリクエストに対する結果や処理のステータスが含まれます。レスポンスは通信プロトコルに基づいて構造化され、HTTPプロトコルの場合、ステータスコード、ヘッダー、ボディなどの要素が含まれます。
レスポンスの構成要素:
- ステータスコード (Status Code):
レスポンスの処理結果や状態を示す3桁の数字です。例えば、200は成功を示し、404はリソースが見つからないことを示します。ステータスコードはクライアントに対して、リクエストが成功したかどうかや何らかのエラーが発生したかを通知します。
- ヘッダー (Headers):
レスポンスに関連するメタ情報や設定が含まれる部分です。例えば、コンテンツタイプ、サーバータイプ、クッキーなどが含まれます。
- ボディ (Body):
レスポンスにデータが含まれる場合、それがボディに格納されます。HTML、JSON、画像データなど、様々な形式のデータがボディに含まれます。ボディは必ずしも含まれるとは限らず、例えばリダイレクト時のレスポンスなどではボディが空であることもあります。
具体例:
- HTTP 200 OKのレスポンス:
ウェブブラウザがウェブサーバーに特定のページのデータを要求し、成功した場合のレスポンスは以下のようになります。
HTTP/1.1 200 OK Content-Type: text/html Date: Wed, 01 Dec 2023 12:00:00 GMT <!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <h1>Hello, World!</h1> </body> </html>
この例では、ステータスコードが200で成功を示し、HTML形式のデータが含まれています。
- HTTP 404 Not Foundのレスポンス:
ユーザーが存在しないページにアクセスした場合のエラーレスポンスは以下のようになります。
HTTP/1.1 404 Not Found Content-Type: text/html Date: Wed, 01 Dec 2023 12:05:00 GMT <!DOCTYPE html> <html> <head> <title>404 Not Found</title> </head> <body> <h1>404 Not Found</h1> <p>The requested page was not found on this server.</p> </body> </html>
この例では、ステータスコードが404でリソースが見つからなかったことを示しています。
レスポンス処理の流れ:
(1) サーバーがリクエストを受信:
サーバーがクライアントからのリクエストを受信し、それに対する処理を開始します。
(2) レスポンス生成:
サーバーは処理結果やデータを含んだレスポンスを生成します。これにはステータスコードの設定、ヘッダーの追加、ボディの構築などが含まれます。
(3) レスポンス送信:
サーバーは生成したレスポンスをクライアントに送信します。これには通信プロトコルに基づく特定のルールに従います。
(4) クライアントがレスポンスを処理:
クライアントは受け取ったレスポンスを処理し、ユーザーエクスペリエンスを構築します。例えば、ウェブブラウザはHTMLデータを解釈してページを表示します。
レスポンスは通信の成否やデータの取得などにおいて非常に重要であり、クライアントとサーバーの間の信頼性を確保する役割を果たします。
5. クッキー (Cookie):
クッキー(Cookie)は、ウェブブラウザがユーザーのコンピュータに保存する小さなデータの塊であり、主にウェブサイトがユーザーに関する情報を保持し、利用者を識別するために使用されます。クッキーはユーザーエクスペリエンスの向上やセッション管理、パーソナライズされた広告などに広く活用されています。
クッキーの構成要素:
- 名前 (Name):
クッキーの識別子として使われる名前です。名前を指定することで、ウェブサイトは特定のクッキーを識別できます。
- 値 (Value):
クッキーに関連付けられたデータや情報の値です。これがクッキーに保存される実際のデータです。
- 有効期限 (Expires):
クッキーの有効期限を示す時間情報です。有効期限が切れると、ブラウザはそのクッキーを削除します。指定されていない場合、クッキーはセッション終了時に無効になります。
- ドメイン (Domain):
クッキーが送信される対象のドメインを指定します。この設定により、同じドメイン内の異なるページ間でクッキーが共有されることがあります。
- パス (Path):
クッキーが有効であるパスを指定します。通常、特定のディレクトリ階層やパス以下のページでのみクッキーが有効になります。
- セキュア属性 (Secure):
セキュアな接続(HTTPS)の場合にのみ、クッキーが送信されるようにする属性です。これにより、クッキーが暗号化された通信経路でのみ送信され、セキュリティが向上します。
- HttpOnly属性:
クッキーへのアクセスをJavaScriptから制限する属性です。これにより、クロスサイトスクリプティング(XSS)攻撃などのセキュリティリスクが軽減されます。
クッキーの使用例:
- セッション管理:
ウェブサイトはクッキーを使用して、ユーザーがサイト上でのセッションを維持します。ユーザーがログインすると、サーバーはセッションIDなどをクッキーに保存し、それによってユーザーを識別します。
- パーソナライズされた体験:
クッキーを使用して、ユーザーの設定や好みを保持し、パーソナライズされた体験を提供します。例えば、ウェブサイトがユーザーの言語設定やテーマの選択をクッキーに保存し、次回訪れた際にそれに基づいた表示を行います。
- 広告ターゲティング:
クッキーを利用して、ユーザーの興味や行動履歴に基づいて広告をターゲティングします。これにより、ユーザーにより関連性の高い広告を表示することが可能です。
クッキーの利点:
- ユーザーエクスペリエンスの向上:
クッキーを使用することで、ユーザーは個々の設定やカスタマイズを保持しながらウェブサイトを利用できます。
- セッション管理:
クッキーを使ってセッション情報を保存することで、ユーザーのログイン状態やカートの内容を維持できます。
クッキーの注意点:
- プライバシーの懸念:
クッキーはユーザーのブラウジング情報を追跡するため、プライバシーの懸念があります。一部のユーザーはクッキーを無効にしていることもあります。
- セキュリティリスク:
クッキーは悪意のある攻撃者によって悪用される可能性があります。セキュアな実装が必要です。
クッキーは一般的に利用されていますが、プライバシーやセキュリティに対する配慮が求められることもあります。最近では、同様の目的でローカルストレージやセッションストレージなども利用されています。
6. プロトコル (Protocol):
異なるコンピュータやシステムが情報を共有し合うための取り決めや規則のセットです。コンピュータネットワークや通信システムにおいて、データの送受信、通信の確立や制御、エラーの処理などを一貫した方法で行うためにプロトコルが使用されます。プロトコルは通信のスタンダードな枠組みを提供し、異なる機器やシステムが互いに理解し合えるようにします。
プロトコルの種類:
データの送受信や通信の確立を規定するプロトコルです。例えば、TCP(Transmission Control Protocol)やUDP(User Datagram Protocol)などがあります。これらはインターネットでの通信において広く利用されています。
- ネットワークプロトコル:
コンピュータネットワークでのデータの送受信や経路の選択を定義するプロトコルです。例えば、IP(Internet Protocol)やICMP(Internet Control Message Protocol)があります。IPはデータパケットの送信と受信を、ICMPはネットワーク上のエラーメッセージの通知を担当しています。
- アプリケーション層プロトコル:
特定のアプリケーションでのデータのやり取りや通信手順を定義するプロトコルです。例えば、HTTP(HyperText Transfer Protocol)やSMTP(Simple Mail Transfer Protocol)があります。HTTPはウェブブラウザとウェブサーバーの間でのデータ転送に使用され、SMTPは電子メールの送信に使用されます。
プロトコルの要素:
- シンタックス (Syntax):
データの形式や構造、通信のフレームワークなど、プロトコルが定める文法規則や形式のことです。これにより、通信相手がデータを正しく解釈できるようになります。
- セマンティクス (Semantics):
データの意味や内容に関するルールや取り決めのことです。これにより、通信相手がデータを理解し、適切に処理できるようになります。
- タイミング (Timing):
データの送信や受信、通信の確立や切断など、時間的な制約や順序を規定する要素です。これにより、通信が一貫した手順で行われるようになります。
プロトコルの例:
インターネットで使用される主要なプロトコルスイートであり、TCPやIPを含むさまざまなプロトコルから成り立っています。これにより、異なるコンピュータやネットワークが相互に通信できます。
- HTTP (HyperText Transfer Protocol):
ウェブブラウザとウェブサーバーの間でのハイパーテキスト文書の転送に使用されるプロトコルです。クライアントがリクエストを送り、サーバーがそれに対してレスポンスを返す仕組みを提供します。
- SMTP (Simple Mail Transfer Protocol):
電子メールの送信に使用されるプロトコルで、メールサーバー間でメールの転送を行います。発信メールサーバーが宛先メールサーバーにメールを送信するための取り決めを提供します。
プロトコルの重要性:
- 相互運用性:
プロトコルは異なる機器やシステムが共通の言語を理解し、相互に通信できるようにするため、相互運用性を確保します。
- セキュリティ:
セキュリティプロトコルは、データの暗号化や認証などのセキュリティ機能を提供し、通信の安全性を確保します。
- 標準化:
プロトコルの標準化により、異なるベンダーや開発者が同じ仕様に基づいてシステムを開発できるため、規模の大きなネットワークやシステムの構築が容易になります。
プロトコルはコンピュータネットワークや通信において基本的な概念であり、異なるコンポーネントやシステムが円滑に協力して動作するために必要不可欠です。
7. ポート番号 (Port Number):
コンピュータネットワーク上で特定のプロセスやサービスにアクセスするために使用される識別子です。TCPやUDPといったトランスポート層のプロトコルを使用する通信において、データがどのプロセスやサービスに届くかを区別するためにポート番号が割り当てられます。ポート番号は0から65535までの範囲で指定され、一部は標準的に使われるものがあります。
ポート番号の種類:
- ウェルノウンポート(Well-Known Ports):
0から1023までのポート番号で、一般的なサービスやプロトコルに割り当てられています。例えば、HTTP(80番ポート)、HTTPS(443番ポート)、FTP(21番ポート)などがあります。
- 登録済みポート(Registered Ports):
1024から49151までのポート番号で、一般的なアプリケーションやサービスに対して登録されています。例えば、MySQL(3306番ポート)、SSH(22番ポート)などが含まれます。
- ダイナミック・プライベート・ポート(Dynamic and/or Private Ports):
49152から65535までのポート番号で、一般的なアプリケーションやサービスに対して登録されていない範囲です。これはクライアントからの一時的な接続に使用されることがあります。
ポート番号の重要性:
- プロセス識別:
ポート番号を使用することで、同じホスト上で複数のネットワークサービスやプロセスが同時に実行されていても、正確に特定されます。
- サービスの区別:
ポート番号により、どのサービスやプロトコルが通信しているかを区別できます。これにより、異なるサービスが同じホスト上で同時に動作できます。
ポート番号の例:
- HTTP (HyperText Transfer Protocol):
標準的なウェブブラウジングに使用されるポート番号は80番です。例えば、http://example.com:80。
- HTTPS (HyperText Transfer Protocol Secure):
セキュアなウェブブラウジングに使用されるポート番号は443番です。例えば、https://example.com:443。
- FTP (File Transfer Protocol):
ファイル転送に使用されるポート番号は21番です。例えば、ftp://example.com:21。
- SSH (Secure Shell):
リモートシェルアクセスやセキュアなデータ通信に使用されるポート番号は22番です。例えば、ssh example.com。
- MySQL Database Server:
MySQLデータベースサーバーに接続するためのポート番号は通常3306番です。例えば、mysql -h example.com -P 3306。
ポート番号の利用:
- プログラミング:
プログラミング言語やフレームワークを使用して、特定のポート番号を指定してネットワークプログラムを開発することがあります。
- システム管理:
システム管理者は、サーバーやネットワークデバイスにおいて特定のポート番号を監視し、トラフィックを制御することがあります。
- ネットワーク構成:
ネットワーク機器やファイアウォールなど、ネットワーク構成においてポート番号を設定して通信を管理することがあります。
ポート番号はネットワーク通信において非常に重要であり、正確なポートの使用は通信の正常な機能とセキュリティを確保する上で不可欠です。
【初心者向け】Vimの基本操作をまとめてみた
Vimは、viから派生した高機能なテキストエディタとして広く使用されていますが、初めて利用する人にとっては取っ付き難く、習得するまでにそれなりに学習コストがかかることがあります。
しかし、一度マスターすると、高度なテキスト編集作業を効率的かつ迅速に行うことができます。
そこで本記事では、これから本格的にVimを学習する人やVim初心者という人に向けて、Vimの基本操作について解説していきます。
1. モード
Vimの基本操作において、モードは重要なコンセプトの一つです。
Vimは異なるモード間を切り替えながら作業を進めることができます。
Vimには、主に以下のようなモードがあります。
ノーマルモード
ノーマルモードはVimのデフォルトモードであり、コマンドを実行するモードです。このモードでは、キー入力がコマンドとして解釈され、テキストの編集やカーソルの移動が行えます。ノーマルモードを駆使することで、各種操作を素早く実行することができるようになります。
インサートモード
インサートモードではテキストを直接入力することができます。ノーマルモードからインサートモードに切り替えるには「i」を押します。このモードでは、通常のテキストエディタと同様に文字を打ち込むことができます。
ビジュアルモード
ビジュアルモードはテキストを選択するためのモードです。ノーマルモードからビジュアルモードに切り替えるには「v」を押します。選択した範囲に対して様々な操作を行うことができます。
これらのモードはVimを使いこなす上での基本であり、これらのモードを状況に応じて使い分けることで、素早い操作やテキスト編集の効率的な進行が可能になります。
2. 基本の移動
Vimの基本の一環として、テキスト内でのカーソルの移動は非常に重要です。以下で、Vimでの基本的な移動コマンドについて説明します。
カーソル移動
- h : カーソルを左に移動します。このコマンドは、左方向への移動に使用されます。
- j : カーソルを下に移動します。通常、行をまたいでの移動に利用されます。
- k : カーソルを上に移動します。行をまたいでの移動に使用されます。
- l : カーソルを右に移動します。右方向への移動に使います。
これらの移動コマンドは、ノーマルモードでの基本的なナビゲーションを行うためのものです。矢印キーを使わずにこれらのキーを組み合わせて使用することで、手をキーボードから離さずに素早い移動が可能になります。
単語単位の移動
Vimはテキストを単語単位で操作することが可能です。
- w : 次の単語の先頭にカーソルを移動します。
- e : 次の単語の末尾にカーソルを移動します。
- b : 前の単語の先頭にカーソルを移動します。
これらのコマンドは、単語ごとの移動が必要な場合に便利です。
行の先頭・末尾への移動
- 0 : カーソルを現在の行の先頭に移動します。
- $ : カーソルを現在の行の末尾に移動します。
これらの移動コマンドを使うことで、行全体に対する操作を効率的に行うことができます。これらの基本的な移動コマンドを覚え、使いこなすことで、Vimでの効率的なテキスト編集が可能になります。
3. テキストの操作
Vimでは、ノーマルモードでのテキスト編集が中心となります。以下は、テキストを効率的に操作するための基本的なコマンドです。
行の操作
- dd : カーソルがある行を削除します。削除した行はクリップボードに保存されます。
- yy : カーソルがある行をコピーします。コピーした行もクリップボードに保存されます。
- p : カーソルの次にテキストをペーストします。ddやyyで削除またはコピーした内容を挿入できます。
文字の操作
- x : カーソルがある位置の文字を削除します。
- r : カーソルがある位置の文字を他の文字に置き換えます。例えば、raと入力すると、カーソルがある位置の文字がaに置き換わります。
ブロック選択と操作
Vimのビジュアルモードを使用することで、特定の範囲を選択し、さまざまな操作を行うことができます。
- v : ノーマルモードからビジュアルモードに切り替えます。
- V : ビジュアルモードを行選択モードに変更します。
- Ctrl + V : ブロック(矩形)選択モードに変更します。
これらのモードでテキストを選択した後、削除やコピー、貼り付けなどの操作が可能です。
これらのテキスト操作コマンドを組み合わせて使うことで、短いコマンドラインを入力するだけで複雑な編集作業が可能となります。しばらくの練習を経て、これらの操作が自然になると、Vimの強力な編集機能をフルに活用できるようになるでしょう。
4. 保存と終了
Vimでの編集が終わったら、変更内容を保存して終了する手順を理解することが重要です。以下は、保存と終了に関連する基本的なコマンドです。
ファイルの保存
- :w : ファイルを保存します。Vimは終了せず、引き続き編集が可能です。
終了コマンド
- :q : Vimを終了します。ただし、もし変更内容が保存されていない場合はエラーが表示され、終了できません。
- :q! : 強制終了コマンド。変更内容を保存せずに無理矢理終了します。扱いには注意が必要です。
保存と終了を同時に
- :wq : ファイルを保存してVimを終了します。これは頻繁に使用されるコマンドで、編集内容を保存して素早く終了するためのショートカットです。
- :x : これもファイルを保存して終了するコマンドですが、もしファイルに変更がない場合は終了しません。
これらのコマンドは、編集作業の終了時によく使用されます。注意が必要なのは、変更内容が保存されていない場合、:qだけでは終了できないことです。その場合は、保存して終了するコマンドを使うか、強制終了の:q!を利用します。
以上、Vimの基本操作について解説してきました。Vimの操作は独特で慣れるまで時間がかかるかもしれませんが、これらの基本的なコマンドを覚え、使いこなすことで、非常に効率的なテキスト編集が可能になります。まずは簡単なファイル編集などからスタートしてみて、焦らず少しずつVimの操作に指を慣らしていきましょう。
駆け出しエンジニアが知っておくべきWeb技術の基本用語
はじめに
この記事では、これからエンジニアになる人、なりたいと思っている人が、仕事を始めてから困らないように、今のうちに知っておくべき代表的なWeb技術の基本用語をいくつかご紹介します。
駆け出しエンジニアが知っておくべきWeb技術の基本用語とは
アプリケーション
アプリケーションソフトウェアの略称で、一般的にアプリとかソフトとか言われてイメージするようなもの。主に以下のような種類に分けられる。
Webアプリケーション
ブラウザの中で動いてインターネットを介して利用するもの。デスクトップアプリケーション
WordやExcelなどパソコン上でインストールして利用するもの。Webアプリケーションの対比として用いられる。ネイティブアプリ(スマホアプリ)
スマホでApp StoreやGoogle Playなどからインストールして利用するもの。ハイブリッドアプリ
Webアプリとネイティブアプリの両方の要素を持ったもの。GmailやX(旧Twitter)などが該当する。
ソフトウェア
物理的実体を伴わず、コンピューターの中で動作するプログラムのこと。
ハードウェア
コンピューターの中で物理的実体を伴う有形の部分。つまり、コンピューターのうち、直接手で触れるものがハードウェアで、触れないものがソフトウェア。
OS
システム全体を管理し、様々なアプリケーションを動かすためのソフトウェア。コンピューターの基本的な人格ともいえるもので、コンピューターの中の土台として動く部分。
リクエスト
ブラウザ(クライアント)からサービス側(サーバー)にWebページなどのデータを要求すること。 リクエストは通常、以下の要素から構成されている。
- リクエストライン: リクエストの種類、リソースのURL、HTTPバージョンからなる。一般的なリクエストメソッドには、GET(データの取得)、POST(データの送信)、PUT(データの更新)、DELETE(データの削除)などがある。
- リクエストヘッダー: クライアントがサーバーに対して送る追加情報やメタデータなど。これらのヘッダーは、クライアントがサーバーに対してリクエストを行う際の情報を提供する。例えば、User-Agentヘッダーはクライアントのブラウザやアプリの情報を示し、Authorizationヘッダーは認証情報を含むことがある。
- リクエストボディ: リクエストがデータを含む場合に、そのデータを含む部分。一部のリクエスト(例: POSTリクエスト)はボディを持ち、データをサーバーに送信するために使用される。
レスポンス
ブラウザからのリクエストを受けて、サービス側がブラウザ側に返す情報のこと。 レスポンスは通常、以下の要素から構成されている。
- ステータスライン: レスポンスのステータスコードとステータスメッセージからなる。ステータスコードは3桁の数字で、200(成功)、404(リソースが見つからない)、500(サーバーエラー)などのリクエストの結果を示す。
- レスポンスヘッダー: サーバーからの追加情報やメタデータなど。これらのヘッダーは、クライアントに対してレスポンスの内容やサーバーの設定に関する情報を提供する。例えば、Content-Typeヘッダーはコンテンツの種類(テキスト、画像、JSONなど)を示し、Dateヘッダーはレスポンスが生成された日時を示す。
- レスポンスボディ: レスポンスの本文で、実際のデータを含む。例えば、ブラウザがWebページを表示するのに必要なデータ(HTML・CSS・JavaScript・画像)などがここに含まれる。ブラウザはこのボディを表示または処理する。
クライアントサイド
リクエストを出すブラウザ側のこと
サーバーサイド
レスポンスを返すサービス側のこと
サーバー
サービスを提供するコンピューターのこと。サーバーはクライアントからのリクエストに応答し、データ、リソース、サービスなどを提供する。
Webアプリケーションサーバー(Webサーバー)
サーバーの中でも、Webアプリケーションが動いているサーバーのこと。単にWebサーバーともいう。WebサーバーはDBサーバーから必要なデータを受け取ったら、ブラウザがWebページを表示するのに必要なデータ(HTML・CSS・JavaScript・画像)などを返す
データベース
データをまとめて管理している仕組みのことで、データを格納し、効率的に検索、管理、更新、操作できるように設計されたデータの集合体のこと。データが入っている箱のようなイメージ。
DBサーバー
データベースが稼働しているサーバーのこと。DBサーバーは、データベースを管理し、データベースへのアクセスを提供する。
RDBMS
リレーショナルデータベース管理システムの略称で、テーブル(表)と呼ばれるExcelのような列(フィールド)と行(レコード)から構成される2次元のデータ構造を使用して表形式でデータを保存する。代表的なRDBMS製品に、MySQLやPostgreSQLなどがある。
プロトコル
コンピューターや通信ネットワークにおいて情報を交換する際の取り決めのこと。リクエストを受け取ってレスポンスを返す時に、どういうリクエストを受けてどういうレスポンスを返すかといったルールが決められている。有名なプロトコルとして、以下のような種類がある。
HTTP
インターネットのWeb通信の取り決めをしたもの。クライアントとサーバーの間でデータのやりとりを行うための規則と手順が規定されている。SSL
第三者にWeb通信の情報が見えないように暗号化する技術のことで、通信の暗号化とデータの完全性を保護するために使用される。HTTPS
HTTPとSSLを組み合わせることで web通信を暗号化して守った形で通信するプロトコルのこと。通信データはSSLを使用して暗号化され、データの完全性と機密性が保護されます。これにより、データが安全に送受信されます。
フロントエンド
HTML・CSS・JavaScriptといったブラウザ側で実行される部分のこと。クライアントサイドともいう。
バックエンド
サーバー側で実行される部分のこと。サーバーサイドともいう。
ライブラリ
プログラムの部品を集めてひとまとめにしたファイルのこと。開発時に使える便利ツール群みたいなもの。 家具ひとつひとつを買い揃えるようなイメージ。
フレームワーク
ライブラリーと同様、便利なコードを集めたもので、かつ全体の処理の流れを枠組み化しているもの。 モデルハウスの家を丸々購入するようなイメージ。
クラウド
インターネット経由でサーバーやネットワーク機器を利用できるようなサービスのこと。自前でサーバーを用意しなくてもクラウドサービスの提供会社が用意したものを利用できる。使った時間単位ごとに課金がされるようなモデルのため、キャンペーンなどのアクセス数が多いときだけサーバー台数を増やして、キャンペーンが終わったらサーバー台数を減らすということが自由自在にできる。代表的なクラウドサービスとしてAWSやGCPやAzureなどがある。
API
プログラムの特定の機能を使うために用意されている窓口のこと。 例えばJavaScriptからバックエンドに対して商品一覧のデータのリクエストを送ったとして、バックエンド側で商品一覧の情報の窓口を用意しておいて、そこにリクエストが来たら商品データを返す。その際の窓口にあたるのがAPIとなる。 APIは自前で用意することもあれば、他社が用意しているAPIを使うこともある。代表的なAPIに、Google Maps APIなどがある。
おわりに
いかがだったでしょうか。すべての用語を知っていましたか? 中には難しいと思われる用語もあったかもしれませんが、エンジニアになったら知っていて当たり前の用語ばかりです。 また、ここでご紹介した用語以外にも、エンジニアの仕事をしていく上で知っておくべき用語というのは、まだまだたくさんありますので、知らない用語を聞いた際には、すぐに調べるクセをつけましょう。